
Computers have constantly been evolving to be easier to use and understand. They are now powerful enough to try and understand humans, rather than needing humans to understand them. Apple’s Siri, Microsoft’s Cortana, Amazon’s Alexa and Google Now are a new kind of interface that relies on asking your device to perform actions, or retrieve data using natural speech. Of course the first step these digital assistants do is to convert the voice data to text using speech recognition. But what then? When you ask Google Now, “What is the cost of the cheapest flight to Sydney leaving August 11th”, after converting that to text it still needs to actually recognise that you are querying flights from your current location to Sydney; that you want to travel on August 11th and that you want the cheapest flight. Traditionally this would involve filling in complex forms. Furthermore you could easily ask: “Which is the cheapest flight to Sydney on August 11th” or just “cheapest Sydney flight august 11th” and you should get the same result. Clearly Google is able to parse the key bits of data in your query and actually act on it.
Natural Language Processing
Natural Language Processing (NLP) is the field of Computer.Science that deals with developing systems that can work with natural language.
While most programming languages and markup is text data that computers need to process, NLP is fundamentally different since most natural languages don’t have a standardised unambiguous syntax.
Natural languages like English can often be very ambiguous. Consider the sentence, “We saw her duck.” Does it reference the act of ducking. Does mean to say we saw a duck that belonged to this person.
Or even that people used a saw on the duck to cut it. We sure hope it wasn’t this last one. Without additional context it’s hard to know what this means. Given our extensive experience with the world, we can say that the first interpretation is most likely and the last one is least likely. After all few people have ducks around and even fewer (one can hope) would need to cut a duck using a saw. On the other hand people duck all the time. And with that knowledge we can reason that it was the first case that happened, unless told otherwise.
Computers can’t intuit the most probable meaning of this sentence like humans can. Or can they? Using machine learning it is possible to train computers to better make predictions about the meaning of text. As you can imagine they need to digest a lot of data to make such decisions (just like we need a lot of experience). If this text came from a speech recognition system, inflection could be an additional context.
Natural language processing then needs specialised tools that are built on data, the more the merrier. In this article we will look at a rather popular open source toolkit for natural language processing called NLTK (Natural Language ToolKit). Since we don’t want Google to go out of business with our cool new language processing software, we will only focus on the very basics. We’ll focus on taking natural language as input, and discovering things about that text programmatically.
Getting, installing and setting up NLTK
NLTK is a Python package that includes a large number of features that have to do with managing, cleaning, importing and processing text. Since it is a Python package, you will need to have Python installed in order to use it. To keep things simple we recommend that you simply download and install Anaconda, a Python distribution by Continuum Analytics.
This Python distribution is available for Windows, macOS and Linux and includes not only NLTK but a number of other popular Python libraries, frameworks and packages that could be of use. You will need the Python 3.5 version of the Anaconda distribution, 32-bit or 64-bit doesn’t matter as much.
https://www.continuum.io/ It’s a large download since it includes a lot of libraries. It’s also possible to download a minimal bare Python version, and install just what you need.
The minimal version is called Miniconda and is about a tenth the size of the complete package. If you pick this option though you will need to install NLTK manually using conda install nltk.
If you already have a recent version of Python 3 installed, you can still try Anaconda / Miniconda, or just install NLTK using pip install –user nltk in your terminal.
The –user ensures that the package is installed just for the current user so you don’t need to use sudo or obtain admin privileges.
There is one more step. While NLTK includes a number of great tools for processing text, it doesn’t include the data those algorithms need to run. There is gigabytes of data available and most people don’t need all of it.
This data is what uses to actually understand language. For instance it doesn’t include a dictionary or other pieces of data necessary for understanding natural language.
NLTK includes a handy tool for downloading this data which you can launch from a Python shell. We will use ipython an enhanced Python shell, since it features code completion and other enhanced features not found in the standard shell available via python. If you installed Anaconda, you can also try jupyter qtconsole for a Python shell that has a GUI, and jupyter notebook which lets you interact with the Python shell in a browser. If you are using your own Python install, or installed Miniconda, you can install ipython and other nice tools using conda install jupyter for Miniconda, and pip install –user Jupyter otherwise. In any case you can launch one of these shells by typing them in the terminal. Now you can type the following in the Python shell (whichever one you use): import nltk nltk.download()
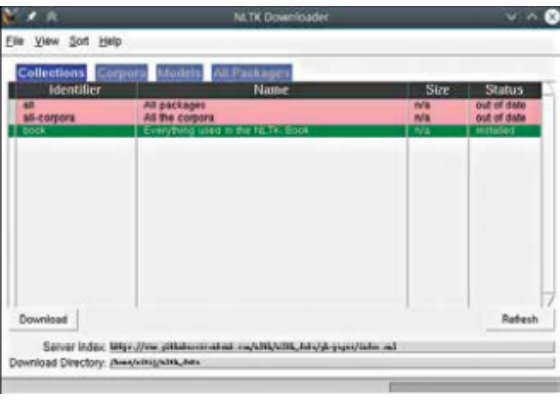
NLTK includes a GUI and a console tool for downloading essential data needed for its operation.
A dialog should pop up that lets you pick the data you want to download. Select “book” since it has a good collection of the data you will need, and it small enough at under 100MB. You can browse other tabs to see what all is available. If at any point you get errors about missing data, you can use this to get it.
Tokenizing text
Tokenizing sounds fancy but it’s simply the act of splitting text into smaller elements (tokens). We might split some text into paras, or sentences, or words. It’s easy to understand, but harder to actually implement. It might seem simple to split by sentence till you realize that you’ll need to look out for cases like “Dr.” or “Mr.”.
Likewise, splitting at words is more complex than just splitting at each space character, especially considering cases like “cannot” and “wouldn’t” which should split, are both contractions of two words.
NLTK includes a collection of tokenisers that can handle all kinds of special cases, not just words, and sentences. These is also a TweetTokeniser that can handle emoji in Tweets. The “book” collection we downloaded in the previous section includes the entire text of a few public domain books.
Let’s open one of them and tokenise it by words. import nltk persuasion_file = nltk.corpus.gutenberg.open(‘austen-persuasion. txt’) persuasion_text = persuasion_file.read() persuasion_words = nltk.word_tokenize(persuasion_text)
In our examples we will use “Persuasion” by Jane Austen. Here we have first opened the included copy of Persuasion which is part of the Gutenberg corpus. We then read in the entire text of that file, and use the included word tokeniser to break the text into words. Try out nltk.word_tokenize(‘…’) on some of your own sentences to see how it handles different cases. You can also see a list of other tokenisers typing dir(nltk.tokenize). If you want more information about one of them you can use the help function. For example: help(nltk.tokenize.TreebankWordTokenizer)
Exploring our Text
To handle large bundles of text, like this entire 250-page book, NLTK had a class called Text. We’ll wrap our persuasion_words data in a Text object to explore it with greater ease. persuasion = nltk.Text(persuasion_words)
Doing this gives us quick access to a number of useful features of NLTK. Let’s start with something simple. Let’s see how many time the title of the book is used within its text. print(persuasion.count(‘persuasion’))
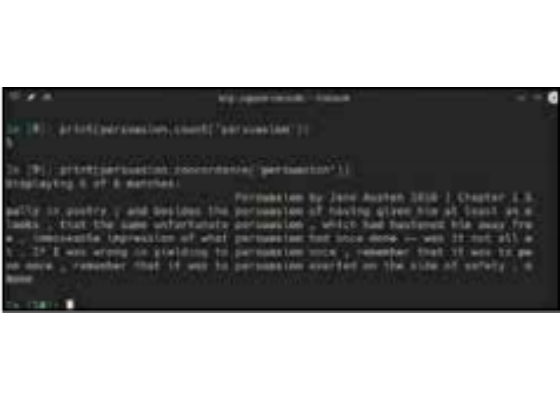
You should get a rather low number of 5. That’s interesting. How about we look at each usage of that word in context. For this we use the concordance tool: print(persuasion.concordance(‘persuasion’)) You’ll find that the first usage of the word is in the title itself. By default this only lists a total of 79 characters around the word, but you can increase that by providing a width parameter. If you’re writing a book report, or otherwise analysing the text of this book, this can be particularly useful. It would also be useful to analyse the characters in the text. Let’s now look at something called a dispersion plot that shows how a word is distributed in

This graph shows how often the Characters along the y-axis are mentioned over the course of the book
the text. Let’s see how four different characters appear throughout the book. persuasion.dispersion_plot([“Anne”, “Wentworth”, “Benwick”, “Dalrymple”]) Looking at the graph you can see how references to these characters are distributed throughout the book. You can tell from the graph that “Anne” is an important character, since she’s mentioned a lot – she’s the protagonist. You can see that “Benwick” is introduced a third of the way through the book, and is central in a few areas but mostly fades out. “Lady Dalrymple” is introduced mid-way through the book and also fades out.
What we’ve done till now has been great, but it doesn’t really need any understanding of the language by the computer to work. Let’s look at a simple concept called stemming.
Stemming
Language – especially the English language – naturally contains many affixed forms for many words. For example, “coding”, “coded”, and “codes” all stem from the word “code”. It can be of great help to break a word down to its core meaning, to its “stem word” as it’s called. You can imagine how useful this would be in a search engine where searching for “coding” should also return results for mentions of “code”, and “codes”.
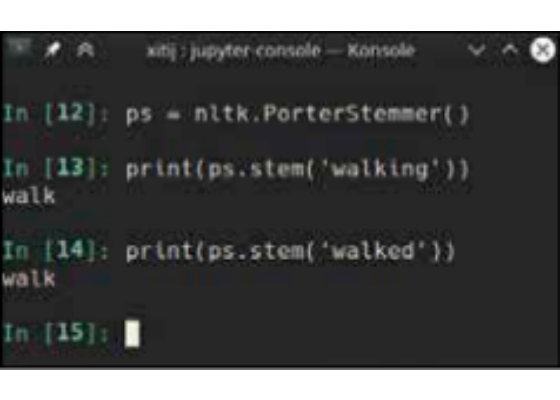
Both the above examples should resolve to “walk”.
NLTK includes a number of stemming algorithms to get to the stem word for any given word. We’ll look at the Porter stemmer, which isn’t the best but is easy to use and fast. ps = nltk.PorterStemmer() print(ps.stem(‘walking’)) print(ps.stem(‘walked’)) There is a more powerful concept called lemmatizing that can go even further, by reducing words based on similar meaning. If you lemmatize “are”, and “is” as verbs they will both resolve to “be”. You can try the WordNet Lemmatizer using nltk.WordNetLemmatizer().
Parts of Speech
You might be familiar with Parts of Speech which classify words as nouns, verbs, adjectives, etc. It could be of immense use in some cases to be able to derive the class of all the words in a sentence. Let’s see how we can have NLTK tag the parts of speech for all the words in a sentence.
sentence = nltk.word_tokenize(‘Anne hoped she had outlived the age of blushing; but the age of emotion she certainly had not.’) print(nltk.pos_tag(sentence)) You’ll notice that we are first splitting the sentence into words, and then using the pos_tag function on this sentence as a list of words. You cannot directly use pos_tag without breaking the sentence into a word list.
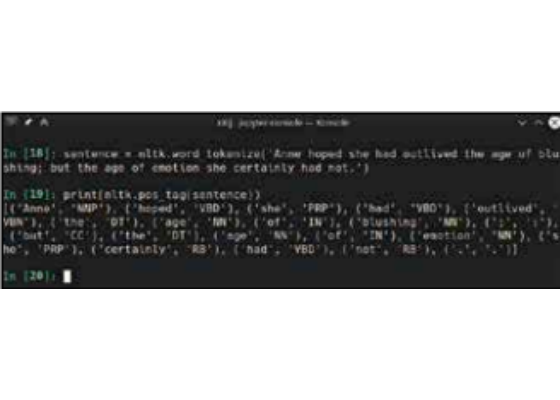
What it returns is a list which pairs each word with its part of speech. Running the above you should have seen: [(‘Anne’, ‘NNP’), (‘hoped’, ‘VBD’), (‘she’, ‘PRP’), (‘had’, ‘VBD’), …] The above is the truncated output, you should see tags for all the words in the sentence, including punctuation.
The codes here, NNP, VBD, and PRP stand for “proper singular noun”, “past tense verb” and “personal pronoun” respectively. You can see all the tags and what they stand for using the command: nltk.help.upenn_tagset(). This is for the UPENN tagset, there are others available.
It’s important to note that the parts of speech identification of a word depend on its context. In the above sentence, “blushing” is tagged as a noun, however the same word would be tagged as a verb in “He was blushing with embarrassment.”
You can see how useful it would be to take a sentence and get its nouns, verbs and adjectives. By knowing the parts of speech involved in a sentence, you can quickly determine the subjects, objects and actions being mentioned.
Chunking
Once you have a tagged sentence, NLTK includes many other tools that operate on it to perform more useful tasks. One such tool is chunking, which allows you to use an extended regex syntax to search for patterns in POS tagged text.
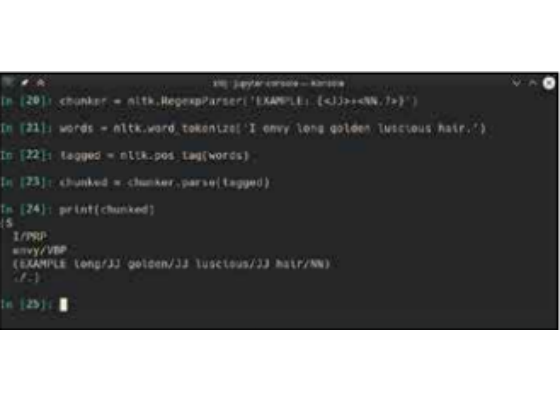
For instance you could search for and tag a series of adjectives followed by a noun, which would tag the sequence “long golden luscious hair” in a sentence. Let’s see this in action: chunker = nltk.RegexpParser(‘EXAMPLE: {+}’) words = nltk.word_tokenize(‘I envy long golden luscious hair.’) tagged = nltk.pos_tag(words) chunked = chunker.parse(tagged) print(chunked)
The first line here initialises our chunker to look for sequences of adjectives followed by the noun they apply to. “JJ” here is code for adjectives, and the “+” in regex means look for one or more.
All kinds of nouns start with “NN”, so “NN.?” means “NN” possibly followed by another character. The text “EXAMPLE” just tells it to tag such sequences as “EXAMPLE”, you could call it anything.
You will see that the output contains this line: (EXAMPLE long/JJ golden/JJ final/JJ luscious/JJ hair/NN) Many operations in NLTK produce Tree objects which can be viewed graphically by calling their draw method. This program has tagged this sequence from the sentence.
You can also try chunked.draw() to see this as a tree graph.
NLTK also includes ready-made code for finding chunks that represent named entities, such as the names of people, places, organisations etc. You can try it on a tagged sentence using nltk. ne_chunk(tagged). There are many more places where such tagged text can be further processed to enhance the kinds of operations you perform on text. Without any training or additionally data, ne_chunk has managed to do a decent job of detecting named entities.
Next Steps
What we’ve covered till now is the very basics of what NLTK is capable of, and even then we looked at NLTK in isolation without considering other useful libraries. A huge part of natural language processing is actually learning from data, developing a model, and using it to better classify text
in the way we want. A good example of that is Sentiment Analysis. Sentiment Analysis software can predict whether a given text conveys a positive, neutral or negative tone. In order for it to work properly, you need to train the software by feeding it examples of positive and negative texts. The more examples you give it, the better the result.
While NLTK gives you access to tonnes of existing datasets, sometimes you might want to create your own. This is especially true if the text you want to work with is very specific to a domain. We have also glossed over the powerful WordNet module. WordNet is a huge collection of words that have been linked together by similarity in meaning (like a thesaurus) but also other relations such as antonyms, hypernyms and hyponyms.
It is also a dictionary, and includes meanings and example usages of words. NLTK also gives you access to a large volume of text in multiple languages (including some Indian languages) to play with. It’s also incredibly easy to import your own text. Finally, NLTK isn’t everything.
There are a number of other packages for Python and other programming languages that focus on different areas of NLP. NLTK is a good place to explore first since it is broad in scope, yet easy to understand and has good documentation and a large number of tutorials from reliable sources available online.

